


What I learnt from building & launching a pure play Gen AI application

This post is not exactly a playbook. But it does cover certain key decision points a product manager or leader needs to make when building Gen AI based products that forms part of a playbook.
It’s part 1 of a follow-up to a sharing session I did with a community of tech enthusiasts in Singapore a few weeks ago. That session covered some key learnings including challenges I faced when we built an entire end-to-end application underpinned by different Gen AI models.
In this post, I want to cover more in depth 3 specific challenges we faced as a product team and how we can overcome those.
Background
I spent a good part of the last year as a fractional CPO helping the founders at 1bstories pivot their business and launch a new “AI based text-to-video app” called Vidiofy.ai . The app helps creators, marketers and publishers convert any text based content to a video. This allows them to repurpose their existing content and create a short form professional video they can use for social media or advertising creatives.

In the process of building this app, we faced several challenges that are quite unique to building apps on top of Gen-AI stack. Although, I’m not new to AI I still had a lot to learn from building this application based on the new generation of AI models. So I thought I’d share that with the community.
Key Challenges :
Lack of commercially available Text-to-Video models
Currently available SOTA (state of the art foundational models) text to video models are still quite limited in what they can do. The main limitation currently is they can create only a few seconds of video (notwithstanding Open AI’s SORA claim to generate 1 minute long clips). Some of the other models include Runway’s Gen-2, Google’s Lumiere, Meta’s Make-a-video though only Runway’s Gen-2 is currently commercially available. I’m pretty bullish this will change quite quickly given the launch of new models and novel architectures such as the transformer/diffusion architecture being used in Open AI’s SORA. has changed this a bit (ex: Runway Gen-2 etc) generate just a few seconds of clips.
The main challenges in text-to-video
Computational challenges: Ensuring spatial and temporal consistency across frames
Lack of high-quality datasets
Vagueness around video captioning
The key ingredients for building such multi-modal foundational models
A world class AI research team
Huge capital (upwards of $50M),
A large amount of high quality training datasets (very difficult to find in the video space unless you own a Video platform such as Youtube, Instagram or Tiktok or you own content IP such as Disney.
And finally access to GPUs. Although NVIDIA seems to be catching up to demand it’s still practically difficult to get access to 1000s of such GPUs. Not to mention the cost. We had wait for a few weeks till we got early access to H100 GPU instances via GCP.
Even with all these, these models can currently can create only small video clips (a few seconds) based on a text prompt from the user. Practically speaking they’re not much different from Midjourney or Stable diffusion right now. Just replace images with a few second clips (such as a bear wearing a hat taking a walk in front of eiffel tower). Again, SORA might change everything but it’s yet to become commercially available.

So what did we do?
In our case, we had a clear problem definition for which we needed to build a solution in quick time (6-8 weeks rather than a few months to a year). So what do we do?
We decided to play at a pure play application level. We built a “workflow” style application that sequentially generated different parts of the video such as the script, background media, background music, speech and lip sync videos using different Gen AI models. We fine tuned and integrated these models into a novel and innovative new workflow tool that allows anyone to repurpose their existing text based content such as this blog into a exciting and engaging short form video that can be distributed on any platform such as Youtube, Instagram or Tiktok. This is in itself a massive challenge for a small startup.
To give you an idea, these are the various modules we built that involve Gen AI.
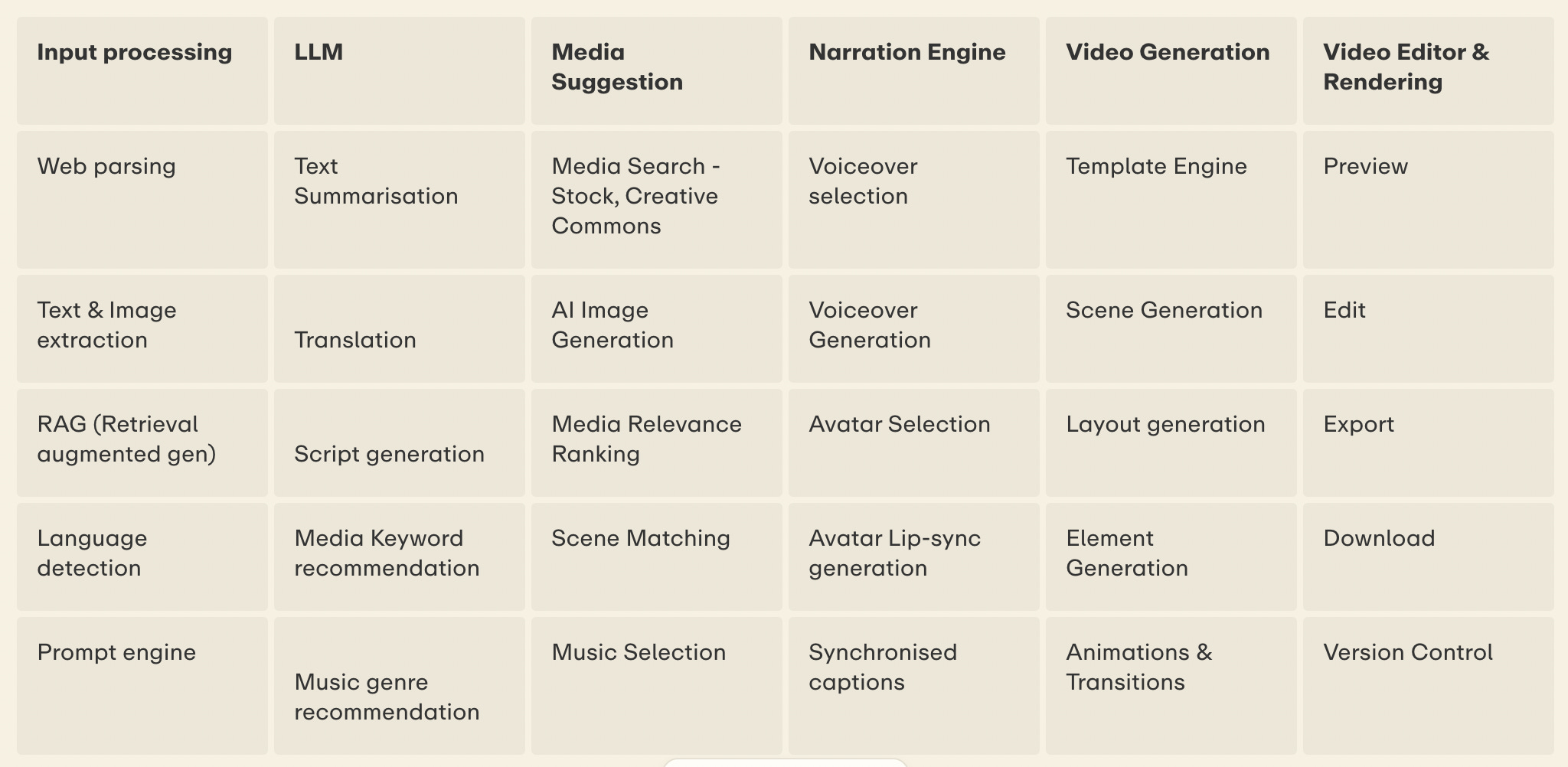
My key takeaways :
You don’t need to be a model company to deliver massive value to users using Gen AI. If you can solve the product and engineering challenges well and hopefully you’ve done your customer research you can build and deliver a compelling product with a massive addressable market (Ex : Video creation). Sure, you might not attract $100M seed round, but then the verdict is still out on whether the high valuations commanded by Gen AI foundational model companies can be justified with revenue growth in the future.
We’re still early on the Gen AI wave when it comes to the application stack. There’s still so much attention (and capital) paid towards foundational models and to an extent on the AI cloud and infrastructure providers. But we’re only beginning to see new novel applications that are possible now that weren’t possible before.
Backend Engineering - Scaling Gen AI based applications is a far more complex challenge
For an app like Vidiofy.ai we needed to use multiple gen-ai models - LLM (OpenAI, Anthropic or Google’s Gemini), Image generation, Image & Video relevance ranking for ranking candidates from stock libraries, Text to speech generation using providers such as Elevenlabs.io and adding AI Avatars such as talking heads or lip synced videos. This causes multiple non-trivial issues as we attempted to scale our app even at a relatively small scale of 1000s of users.
Integration with 3rd party APIs mean we needed to stress test their APIs for Speed / latency, concurrency and failure rates.
Multiple points of failure requires a fail-safe robust backend architecture. Our backend team has always been busy since launch trying to optimise and re-architect our solution. Usually in traditional SaaS you wouldn’t do this until you hit a certain scale. But with our multimodal Gen AI application and their nature of heavy processing you’ll need to have sound backend systems and architecture design much earlier.
Economy of scale is much more difficult to achieve. What you had in traditional SaaS where the marginal cost of servicing each user goes down with more users doesn’t apply anymore. We had to really optimise our pipelines to ensure costs don’t scale linearly. I intend to cover cost implications in a dedicated post.
Hosting individual models can be prohibitively expensive. Although there are cheaper and higher performant models now available such as Mistral’s 8x7B mixture of experts model, you are still beholden to cloud costs from AWS and GCP servers not to mention the scarcity of H100 GPUs (ex : image, voice, avatars).
Consider using on-demand GPU based Cloud services such as Replicate or Runpod.io to ensure it’s on-demand. Do remember we faced some challenges with both their customer service and cold start, but this is probably for another day.


Product UI/UX Design - Prompt or Workflow UI?
Why is this a problem?
Traditional SaaS products usually have a multi-step form based UI. SaaS products typically take user inputs with structured forms (some text fields, drop-downs and file uploads) and once submitted process this and provide an output (or a result of the processing). This works really well when we’re building workflow based tools. For example, someone who needs to record, edit and publish a podcast is following a specific workflow. This kind of “workflow“ application is best achieved using a multi-step form based UI instead.
Prompt based UI
A vast majority of popular Gen-AI products such as chatGPT & Midjourney have a prompt based UI. Usually this contains a single text input field for what we call a “prompt“. A user usually mostly provides a text prompt ( a set of instructions in natural language to get a desired output). By extension a user may also provide an attachment as additional input - typically a file (such as document, image or video) or a URL.
Such prompt based UI applications work best when the application itself is a “thin wrapper” over a foundational model such as LLM (GPT-4) or a Diffusion model such as (SD). This is notwithstanding any additional processing done on the user prompts using the application’s backend (separate from the foundational model). augmentation input & output artefacts are quite simple.
What we did in Vidiofy
In Vidiofy.ai’s case we launched what is a traditional SaaS workflow based UI, since a user is trying to convert and control how exactly they want the video to look. But a lot of our users were trying “Video prompts“ on our tool though we clearly mentioned it wasn’t built for this.
We did consider a prompt based video generation. But since we’re purely at the application level and don’t build our own foundational models, this would require the following
A fine tuned LLM based trained our prompt to instruction set mapping (i.e when i say i need a video with 5 scenes with a male narrator voice whose voice tone is meditative, we’d need some way to map that to our internal api parameters such as num_scenes=5, narrator_gender=male, voice_tone=meditative.
We’d need to educate our users on the right way to use prompts. Note, a prompt based UI means the range of inputs from users is “unlimited”. But since a workflow app can only do a limited amount of tasks, it’s considered pretty narrow.
We’d need to clearly define the “boundaries” of these prompts. What can the user say or cannot say? For a narrowly defined workflow tool this can cause user frustration. After all a user doesn’t know what they don’t know. In other words, learning prompts in itself becomes a burden for the users and this will mean only advanced / power users can immediately get the most value out of our application (hence blogs and even courses dedicated to chatGPT and Midjourney prompts).
So which one’s best for your application?
Prompt based UI or a Workflow style UI? Like everything else in product, this depends on the specific problem your application is solving for a specific user base.
Some general principles where they might be the UI of choice in the future.
If your application is about information retrieval such as an Q&A assistant, helpdesk chatbot - then prompt or chat based UI could be better because the user can just type in natural language and get their answers without having to browse though pages of your knowledge base or help center.
If your application is designed to generate a single output such as images, text paragraphs from which a user can choose one, then a prompt based UI might be the suited better. But if that output artefact requires complex editing, then you’ll probably need to add a traditional UI anyways. Remember Multi-modal gen AI applications will still requires nifty UI/UX for editing.
For workflow applications, most of your UI is better off being traditional (while it can contain 1 or 2 steps where they generate an output first) before proceeding to save, edit and export that output using a traditional UI.
Designing for asynchronous flow
Most traditional SaaS applications are designed for a Synchronous workflow. That is, the user “waits” for the application’s backend processing to complete their inputs. But, Video generation is a time consuming task. A 1 minute video can take a few minutes to generate. This is even after obvious backend optimisations such as parallel processing (of elements which can be generated in parallel) but you’ll still have sequential bottlenecks in the generation. Once could also consider adding multiple servers with distributed load balancing to cut the overall wait time, but that increases your cost even at a small scale.
As my personal rule of thumb while building products, if a user needs to wait more than a minute for a task to complete then you might be better off designing an asynchronous workflow. A user enters their input and instead of passively “waiting” they are told a job has started and they’ll be notified when it’s done via notifications (email or in-app). When the task is completed, user is notified and they can see the result of the generation and continue their work.
This has obvious implications on the backend which needs to support a task / queue based system with status updates but equally changes lots of things on the application’s UX flow and front-end design.
Implications on Backend
Your API now needs to return a task status instead of the output of the processing and
You now need to support notifications as well (both email and in-app)
This makes the backend architecture more complex (considering this is only our initial launch of the application).
Implications on Frontend
Your UX needs to support task status management
Your UX needs to bring back the user quickly using deep-links from email notifications to review the generated ouput.
Your UX can also try and engage the user while they wait - for example, complete an onboarding form, play a game OR browse through outputs other users have generated and shared). The last one is especially powerful and one that Midjourney uses very effectively since they have a public channel on discord which shows all the generations shared by various users.
Implications on Product Metrics (TTV)
Another impact is also your product’s engagement metrics especially TTV (time-to-value).
TTV or time to value measures how long it takes for a first time user to get value or the “AHA” moment when they first use your product. This is super critical to ensure high retention and repeat use cases.
Lower the TTV, higher the chance for better retention and paid conversion. This metric is especially critical for PLG (product-led growth) style products where a business is trying to drive user and revenue growth through a DIY sign-up & usage flow.
While designing PLG applications, a good product team would (or should) try to design a UX flow that minimizes TTV. This ensures the user sees “immediate value” from trying your product thus enhancing both retention and paid conversion. There might be exceptions for Enterprise SaaS products which need users to integrate with their system or ingest their data but usually these will involve a “sales demo” and a team who’ll hand-hold users through on-boarding so they can get value from the application.
But an asynchronous generation flows means a user is notified of the task after it’s completed. So a user might have to come back and finish their task on a second session (no saying if they come back after just a minute or a day). We can try to engage the user to “do something else” while they wait like above, but even then this will definitely have an impact on the end conversion funnels. The longer it takes longer for a user to get immediate value from an application the users will start dropping off your conversion funnels.
Consider these before you release your first version of Gen AI based product :
Product UX needs to consider asynchronous flow from Day 1 - a clean UX design experience with backend support for notifications and bringing back users to review their generated output.
Engaging the users while they “wait” - by prompting them to browse, learn or complete an onboarding tour.
Part 2 - coming soon :
I plan to cover my learnings on the following challenges in future posts. Stay tuned in this space.
Don't forget your costs
Adding User Feedback Loops
LLM Hallucinations
Are there more challenges you’ve faced with Gen AI. Please add in the comments and start a dialogue.